在垂直服务电商领域,数据化运营已成为提升产品竞争力、优化用户体验和驱动业务增长的核心引擎。而这一切的基石,正是高效、精准、可靠的数据处理服务。它如同整个数据化运营体系的“中央厨房”,将原始、杂乱的数据原料,加工成可供分析、决策、应用的“美味佳肴”。
一、 数据处理服务的核心价值与定位
垂直服务电商(如在线教育、医疗健康、家政服务、旅游预订等)具有需求明确、用户决策路径长、服务非标化、履约环节复杂等特点。其数据化运营分析不仅关注流量和交易,更深度涉及用户生命周期价值(LTV)、服务交付质量、供需匹配效率、复购与口碑等维度。因此,数据处理服务在此场景下承担着关键使命:
- 多源异构数据整合:打通App端、Web端、小程序、客服系统、ERP、CRM、第三方平台(如支付、地图、评价)等多渠道数据,构建统一的用户与业务视图。
- 服务过程数据化:将非标服务的预约、沟通、履约、验收、评价等环节进行结构化记录与量化,形成可分析的服务质量指标体系。
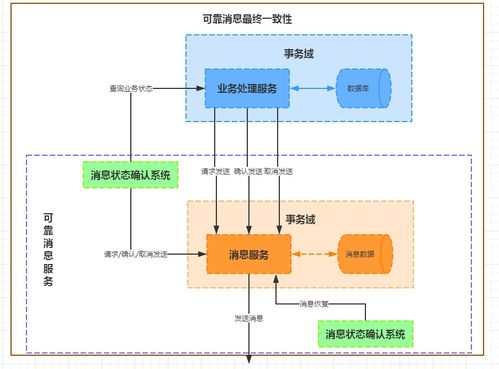
- 实时与离线处理并重:既要支持实时监控(如服务订单状态、资源调度情况、异常告警),也要进行深度的离线分析(如用户分群、服务品类趋势预测、运营活动复盘)。
- 保障数据质量与安全:确保数据的准确性、一致性、及时性,并严格遵守数据隐私法规,对敏感信息进行脱敏加密处理。
二、 数据处理服务的关键流程与技术栈
一个完整的垂直服务电商数据处理服务通常遵循以下流程,并依托相应的技术栈实现:
- 数据采集与接入:
- 方式:埋点SDK、日志收集、API同步、数据库直连等。
- 要点:制定统一的数据采集规范,确保关键行为(如浏览服务详情、预约咨询、完成支付、提交评价)被完整捕获。
- 数据清洗与标准化:
- 任务:处理数据缺失、异常值、格式不一致问题;将非标服务信息(如服务描述、用户评价文本)通过NLP技术进行标签化、情感分析等初步结构化。
- 技术:通常使用Spark、Flink等分布式计算框架编写清洗规则脚本。
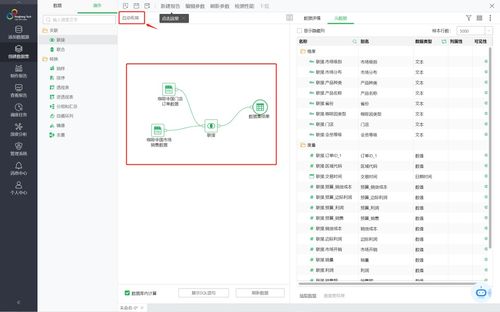
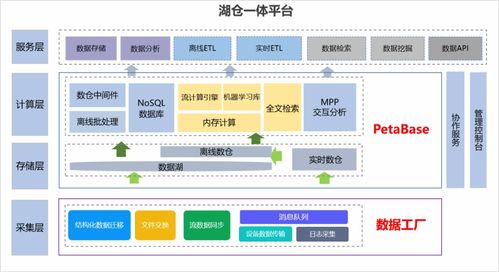
- 数据存储与管理:
- 分层存储:构建ODS(操作数据层)、DWD(明细数据层)、DWS(汇总数据层)、ADS(应用数据层)等数据仓库层级。
- 选型:HDFS、Hive、ClickHouse用于海量离线存储与查询;Kafka用于实时数据流;Redis、HBase用于高速缓存与查询;对象存储用于非结构化数据。
- 数据建模与开发:
- 核心:构建贴合垂直业务的数据模型,如用户360°画像模型、服务供给模型、订单生命周期模型、资源效能模型等。
- 工具:依赖数据开发平台(如DataWorks、Airflow)进行ETL任务调度、依赖管理与监控。
- 数据服务与应用:
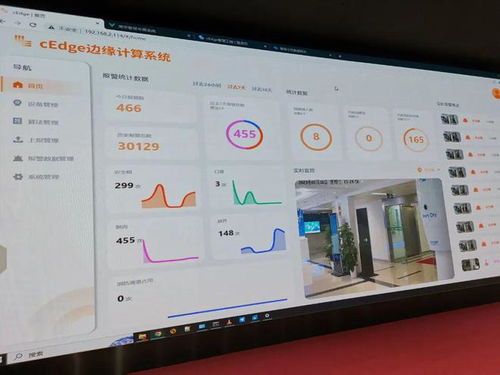
- 输出形式:通过API、数据报表、可视化仪表盘、实时数据推送等方式,将处理后的数据提供给运营、产品、市场、管理层使用。
- 典型应用:个性化推荐(服务/技师推荐)、动态定价策略、智能客服辅助、服务资源智能调度、运营活动效果分析看板。
三、 面向分析场景的数据处理服务实践
数据处理服务必须紧密围绕具体的运营分析场景来设计和优化:
- 用户增长分析:处理渠道来源、拉新成本、激活转化漏斗数据,识别高价值渠道与用户群体。
- 用户体验与留存分析:串联用户从搜索、比价、咨询到履约、评价的全链路行为数据,分析流失节点与服务痛点。
- 供给端效能分析:处理服务提供者(如老师、医生、技师)的接单率、服务质量评分、用户评价等数据,优化供给管理与培训。
- 商业智能与预测:基于历史订单、季节性、市场活动数据,预测不同服务品类的需求趋势,辅助库存(服务能力)管理和营销预算规划。
四、 挑战与未来趋势
挑战:数据孤岛问题在复杂系统架构中依然存在;非标服务的数据化难度高;实时分析与决策对数据处理延迟要求苛刻;数据合规成本日益增加。
趋势:
1. 实时化与智能化:流批一体数据处理架构成为标配,AI/ML模型被更深度地集成到数据处理管道中,实现实时特征计算与智能预警。
2. 自助化与平民化:通过建设完善的数据中台与自助分析工具,降低业务人员使用数据的门槛,让数据更直接地驱动一线运营。
3. 云原生与一体化:基于云平台的数据湖仓一体解决方案,提供更弹性、更集成、更低运维成本的数据处理能力。
4. 隐私计算应用:在数据融合与联合分析中,采用联邦学习、安全多方计算等技术,在保护用户隐私的前提下挖掘数据价值。
结论
对于垂直服务电商产品而言,卓越的数据处理服务并非简单的技术后台,而是数据化运营的“心脏”与“神经中枢”。它通过系统化、工程化的方式,将业务转化为数据,再将数据转化为洞察与行动力,最终实现服务体验的优化、运营效率的提升和商业模式的创新。构建与之匹配的数据处理能力,是垂直服务电商在激烈市场竞争中构筑核心壁垒的关键一环。