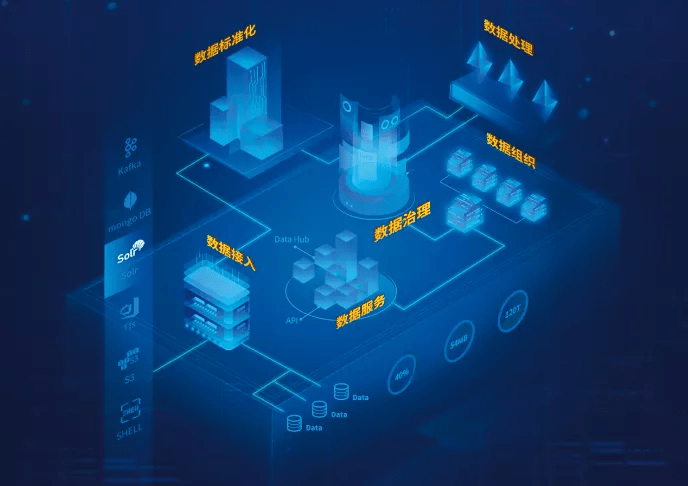
随着大数据技术的迅速发展,基于大数据的舆情分析系统已成为政府、企业等机构监测和管理舆论的重要工具。其中,数据处理服务作为系统的核心组成部分,承担着数据采集、存储、清洗、计算与分析等关键任务。本文将重点探讨数据处理服务在舆情分析系统架构中的设计与实现。
数据处理服务的基础是数据采集模块。该模块通过爬虫技术、API接口等方式,实时或定时地从社交媒体、新闻网站、论坛等渠道获取舆情数据。这些原始数据多为非结构化或半结构化形式,包括文本、图片、视频等多种类型。为了确保数据的全面性和时效性,采集模块通常采用分布式架构,支持多源数据的并行获取,并能够处理高并发请求。
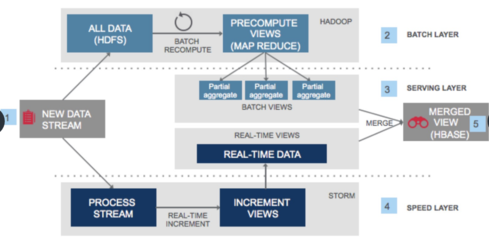
数据存储与清洗模块负责对采集的原始数据进行预处理。由于原始数据往往包含大量噪声、重复或无效信息,清洗过程必不可少。该模块通过数据去重、格式标准化、缺失值处理等技术,提升数据质量。存储方面,系统通常采用混合存储策略:使用HDFS或云存储服务存储海量原始数据,同时利用NoSQL数据库(如HBase、MongoDB)存储清洗后的半结构化数据,以便后续快速查询。
数据计算与分析模块是数据处理服务的核心。该模块依赖于大数据计算框架,如Spark或Flink,进行实时或批处理计算。在舆情分析中,关键任务包括情感分析、主题建模、热点检测等。例如,通过自然语言处理(NLP)技术,对文本数据进行情感极性分类,识别正面、负面或中性情绪;使用聚类算法(如LDA)挖掘舆论主题;结合时间序列分析,动态监测舆论热点变化。该模块还支持实时流处理,能够对突发事件进行即时响应。
数据处理服务通过数据接口层与系统的其他组件(如可视化前端、预警模块)进行交互。处理后的数据以结构化形式输出,供上层应用调用。为确保服务的可靠性和扩展性,系统通常采用微服务架构,将数据处理任务分解为多个独立的服务单元,实现资源弹性分配和故障隔离。
数据处理服务在基于大数据的舆情分析系统中扮演着枢纽角色。通过高效的数据采集、存储、清洗和分析,它不仅提升了舆情数据的可用性,还为决策者提供了及时、准确的舆论洞察。未来,随着人工智能和边缘计算技术的融合,数据处理服务将进一步优化,助力舆情分析系统实现更智能、更实时的响应能力。